Workflow
Making Gitlab the beating heart of our workflow allows us to have a single source of truth about the status of a project, the development experience built around this system will have as values:
- Continuous improvement: The process is not rigid, it brings together heterogeneous experiences faced by AgileLab in the implementation of projects for customers, these experiences must continuously converge in the development process.
- Democracy: The process is not rigid, it provides a way for change, as long as it is shared by all the actors involved.
- Recursiveness: The process by which the process is developed and modified is the process itself (eat your own dogfood)
- Visibility: The process must be able to give visibility on the status of the project at every level of detail necessary, this involves the timely collection of information at multiple levels of detail:
- Gitlab Issues (Visibility on High level Design, Low level design, Work items)
- Merge request (Visibility on the integration of work items within the repository)
- Code Quality (Visibility on the quality of effort delivered)
- Reproducibility:
- The process must be able to answer questions in this format:
- Given an output
O, at what stage of the process was it produced? - Given an output
O, from which inputIwas produced?
- Given an output
- The process must be able to meet this requirement:
- Be
Ethe set of environments for executing builds - Be
Iset of inputs to the build - Be
Othe set of outputs of a build - Be
Tthe set of time instants - Be it
B(i,t,e) : I x T x E -> Oa build process - Given an input commit
i0 ∈ Ian output artifacto0 ∈ Oproduced at the timet0 ∈ Ton a build environmente0 ∈ Efor whichB(i0, t0, e0 ) = o0this equivalence holdsB(t, i0, e) = o0 ∀ t ∈ T , e ∈ E
- Be
- The process must be able to answer questions in this format:
- Automation: The process must consist mostly of tools and not of manual procedures, which favours the expression of the development process itself in the form of code.
[!NOTE] ℹ️ Just added a new section with git squash and merge cheat sheet 🎉
Project layout on gitlab.com
All code repositories should be created on gitlab.com with the following structure:
.
└── AgileFactory
└── Group name
└── Project name
The Group name should mirror the name of the sharepoint group associated with the project
The developers group should host projects related to internal developer experience, the current layout can be an example of the desired layout for other projects
.
└── AgileFactory
└── developers
├── scaffolds
├── microbenchmarks
├── docker
├── Agile.Gitlab.Cli
└── Agile.Commons
Relevant Gitlab administration roles
If you need:
- New repository creation
- Change of administrative settings at the group level
- Creation of new sub groups
- Change of settings you do not have permission to change
please ask to some who is currently energizing the Internal IT/Servizi Sviluppatori role.
if you do not know who is currently energizing the role please ask a question in the BigData/handbook Teams channel
Development model
The development cycle begins with the reception of a document containing the high-level design (HLD) provided by the Architects circle and the opening of a new gitlab repository that will serve as a container for all development activities.
The development model is iterative and based on the concept of sprint, that is a time unit within which all the steps of the project lifecycle are performed, with the aim of having light and fast release cycles and to reduce the presence of activities difficult to complete due to a time horizon too far away.
Concentric system
The development system to be adopted is of a concentric nature and based on 3 levels of granularity, corresponding to increasing levels of decomposition of the project:
- High level design
- Low level design
- Work item
the decomposition of the project takes place through the creation of gitlab issues annotated with their level of granularity
Issues at the same level of granularity are grouped in milestones, so we will have three types of milestones:
- High level design milestone
- Low level design milestone
- Sprint milestone
Milestones are concentric, a low level design milestone is composed of one or more sprints, a high level design milestone is composed of one or more low level design milestones, this type of organization allows you to update information at a higher level of abstraction based on the outputs and knowledge acquired during the course of the milestones of lower level.
Issues
The reference tool for tracking and managing developments is gitlab issues, issues should as far as possible be structured according to the INVEST model
Independent
The issue should be autonomous, so that there is no inherent dependence on another issue.
One of the features of Agile Methodologies such as Scrum, Kanban or XP is the ability to move issues, taking into account their relative priority. If you find strictly dependent issues, a good idea would be to combine them into a single issue.
Negotiable
Issues are not explicit contracts and should leave room for discussion.
The only thing that is fixed in an agile project is the backlog (and even then, this can be clarified).
While the issue is in the backlog, it can be rewritten or even discarded, depending on the business needs, the market, the technical requirements or any other type of request from the team members.
[!Warning] The issue is negotiable while it is in the backlog, when an issue is planned to be executed in a milestone the team has already committed to implement it as described, if there is still uncertainty about what to do when executing a planned issue, the team during the retrospective meeting should discuss about how to improve the planning process
Valuable
Issues must add value for stakeholders.
The main objective is to provide stakeholders with real project value. Inventing technical issues that do not bring value to stakeholders violates one of the principles of agile methodologies, which is to continuously provide software with value.
Estimable
You always have to be able to estimate the size of an issue.
If the size of an issue cannot be estimated, it will never be planned or commissioned; in this way, it will never become part of a sprint. Therefore, it makes no sense to keep this type of issue in the backlog. Most of the time, the estimate cannot be made due to the lack of supporting information in the description of the issue itself, so it must be iterated on the description of the issue in order to clarify these doubts.
Small
Issues should not be so large that they become impossible to plan/prioritise with the right level of confidence.
Try to keep the size of the issues around a few person-days and at most a few person-weeks (a good rule of thumb is that every single backlog issue does not require more than 50% of a sprint; for example, a single issue will not require more than 5 days for a 2 week / 10 day sprint). Anything that goes beyond this range should be considered too big to be estimated with a good level of security.
Issues that do not fit in the "small" definition can be called "Epic", where an epic will last more than one sprint and, necessarily, will have to be divided into smaller issues that can fit comfortably within a sprint. There is no problem in starting with issues in the form of epics, provided they are split when the time to plan them in a sprint approaches.
Testable
The issue or its description shall provide the information necessary to enable the development of the tests.
An issue should only be considered completed if it has been successfully tested. If the result of an issue cannot be tested due to lack of information (see "Estimable" above), the discussion should not be considered planned in a sprint. This is particularly true for teams using TDD - Test Driven Development.
Labels
On gitlab it is necessary to organize the issues through the use of labels, in order to make it possible to create custom views on issues with a certain meaning.
The format of the labels is namespace:name.
Namespaces
Granularity
The granularity namespace collects the labels that identify the design level of an issue or its direct implementability
granularity:high-level-design
The issue noted with this label represents a high-level design element, something that needs to be discussed at system or architectural level, captures business requirements.
granularity:low-level-design
The issue noted with this label represents an element of low level design, a way of clarifying ideas well at the implementation level before starting to develop, in this type of issue decisions will have to be made such as:
- Standardization of resource nomenclature conventions
- Path on hdfs
- Tables on database
- API Layout
- Format of requests/replies
- Required fields
granularity:work-item
The issue noted with this label represents an implementable and self-contained element, the developer must be able to complete the work described in an issue of this type within a single sprint.
Verb
The verb captures in a single word what the assignee of an issue is expected to do for the issue to be declared concluded.
Assigning a verb to an issue also represents the willingness to give the assignee the opportunity to have full power to deal with the issue as he sees fit.
verb:act
The assignee of the issue must act, implement, carry out an action himself
Examples
- Implement reading from json files
- Updates the documentation
- Configure the datanode heap
verb:communicate
The assignee must communicate with a third party, with another team, with another company, so that the subject of the issue is declared concluded.
Examples
- Notify Mario Rossi of the results of the tests
- Informs the customer of the status of developments
- Ask the circle of architects for confirmation of the decision made regarding hdfs
verb:decide
The assignee is responsible for deciding something without having to seek consent
Examples
- Decide which technology to use
- Decide if you want to continue with pair programming
verb:think
The assignee must think of a solution to a problem by reporting it on the issue
Examples
- Find a way to make a persistent connection through a firewall
- Pros and cons of mqtt usage
verb:understand
The assignee must understand a technology, a system, a requirement
Examples
- Understand if kafka suits us
- Understand if the system does work properly
- Understand if the requirement has been implemented correctly
Kind
Represents the type of issue
kind:feature
The issue represents a functionality to be implemented
Examples
- Implement reading from json files
- Updates the documentation
- Configure the datanode heap
kind:hotfix
It's a bug to be fixed
Examples
- Json files are not written correctly
- The configuration is not loaded correctly
kind:meeting
Represents the agenda of a meeting
Exemptions
- Planning meeting
- Review meeting
- Retrospective meeting
Phase
Represents the progress of an issue
phase:in-progress
The issue is currently being processed
phase:blocked
The issue was in progress but due to an unexpected hiccup it is not possible to continue with the work.
This makes it clear to the team that something has jammed, this phase should not be used to model precedence but only to signal that the normal process of development is not working
phase:reviewing
The processing of the issue has been completed, it is possible for the maintainer to proceed to the code review and merge of the developments
Namespaces and custom labels
It is always possible to create custom namespaces.
You can create custom labels within all namespaces.
Milestones

| Type of Milestone | Type issue | Duration | Examples | Description |
|---|---|---|---|---|
| High Level Design | granularity:high-level-design | Follows the project delivery milestones | POC, Minimum Viable Product, Industrialisation | Design level marker, captures business needs |
| Low Level Design | granularity:low-level-design | Fraction of the duration of the HLD milestone | Low level design iteration 0, Low level design iteration 1 |
Conceptual type milestones,
represents a way of decomposing
the high level requirements in
more granular issues, this type of
of issues capture technical decisions which do not involve
writing code, for example:
|
| Sprint | granularity:work-item | Fraction of the duration of the LLD milestone | Sprint 0, Sprint 1 | Operational milestone, collects clear and self-contained elements, an issue for each feature |
Milestone Events

| Event | Description | Duration |
|---|---|---|
| Planning | The team reviews the list of non-milestone issues for the reference granularity level and reaches a consensus on what can be achieved by the team within the milestone time horizon, the planning of a milestone can influence the content of the milestone at the highest level so as to integrate any input resulting from a higher degree of awareness achieved thanks to work carried out at a lower level of abstraction | 2h for each week of milestone duration |
| Review |
The team reviews what has actually been achieved within the milestone, and what could not be achieved within the milestone is transported to the next milestone for the same level of granularity. The team makes a demo to involve all the actors involved and keep them informed of the state of maturity of the work, this allows those who do not actively participate in the development of the project but are only interested in the output (stakeholders) to be able to influence the direction of the project in an iterative manner. The review may result in new issues to be planned |
1h per week of sprint duration |
| Retrospective |
The team discusses the way they work, for example:
The retrospective event must also have the function of reporting feedback on the development methodology, so as to evolve this document of guidelines to capture all good practices that have emerged during teamwork and to remove any obstacles that may have been encountered. |
1h per week of sprint duration |
[!Note] If the events of more than one level fall at the same time, their duration is not summed but a single event is carried out in order to absorb the fixed costs related to the meetings (check-in, call, agenda, minutes...).
[!Danger] All meeting should have as an output a report, this report can be drafted in the gitlab issue associated to the meeting and than committed to the repository as a markdown file

High level design and Milestone Projects
| Input | Intermediate products | Output | Review |
|---|---|---|---|
| High level design document produced by the architects | Issue with granularity:high-level-design |
|
Carried out at the end of each high level design milestone |
The HLD document is decomposed by the development team into gitlab issues with the label granularity:high-level-design these issues capture the essence of the high level design document making it linkable by other issues, the high level design issue is considered concluded when all the elements of low-design associated with those of high-level-design have been concluded.
Low level design and milestone Conceptual
| Input | Intermediate products | Output | Review |
|---|---|---|---|
| Issue of high level design | issue with granularity:low-level design |
|
Carried out at the end of each low level design milestone |
Low level design issues should as much as possible reflect a decomposition into components of the software system to be implemented, these issues must be noted with the label granularity:low-level-design, low level design issues are considered concluded when all work-items associated with low level design issues have been concluded.
Work item and Development Sprint
| Input | Intermediate products | Output | Review |
|---|---|---|---|
| Issues that can be implemented | issue with granularity:work-item |
|
Carried out at the end of each low level design milestone |
A work item is a self-contained element that can be implemented on which to act, a commitment that can be supported by a developer independently within a sprint, this promotes the creation of issues actually achievable without loss of focus with respect to the goal, if the issue once passed to implementation is too laborious for the length of the sprint or not easy to understand the developer himself provide to rework the issue scope decomposing it into further issues. This iterative approach leads to convergence towards a well-structured feature backlog.
The work items resulting from the decomposition of low level design must be noted with the label granularity:work-item, to distinguish work items of different nature you can use the labels in the namespace kind: for example kind:feature,kind:hotfix.
Release
Each milestone will be mapped to a release, the milestone can be external or internal, an internal milestone involves an internal release, an internal demo or simply a check on the progress of the project, an external milestone involves an external release and then the creation of all the formal deliverables required by the project.
Mode of execution of the development sprint
Each developer proceeds to extract a feature for the current milestone from the planned milestone on gitlab, from here begins the life cycle of a feature, the following activities are concurrent, they are not carried out in the order in which they are presented in the document and can proceed in parallel.
- Elaboration of gitlab issue representing the feature with details on the implementation, useful resources, links to internal and/or external documentation, links to other repositories, literature
- Feature implementation
- Unit test implementation
- Integration implementation test
- Feature documentation
At the end of the implementation, the developer will indicate that the feature is ready to be integrated, this will be done by opening a merge request. One or more developers (other than the one who implemented the feature) will review the implementation.
The primary goal of code reviews is to keep the quality of the code above a wanted standard and avoid bugs. Other (usually underestimated) goals of practicing code review are:
- code and knowledge sharing
- view the problem from a different perspective
- mentoring, both for the reviewer and the author
- team code ownership, the reviewer is owner as much as the author
Code Review is not a gate keeping moment. Senior and Junior developers both need code review (no one is infallible) and no one will ever be in a position where feedback is not valuable.
No one should ever accept "code" which he does not understand. If something is not clear, ask clarification, even if it might be due to a lack of knowledge from your side (doing some research beforehand is encorauged though, but just because reading is faster than talking/writing not because we don't want to bother our colleagues). In this way you will clear the doubt and make you more proficient in the future in that scenario.
[!Note] Google opensourced internal code review guidelines, we want to use those as if they where internally created in AgileLab because we found them reasonable and complete, please refer to the github hosted Google code review guidelines and substitute mentally
CLwithMerge Request
The following properties should be verified:
Style
- Adherence to style rules
- Adherence to design patterns
- Presence of known bugs
- Consistency with the software project
Effectiveness
- Adequacy of implementation
Maintainability
- Suitability of the unit tests and their coverage
- Adequacy of integration tests
- Adequacy of documentation
The auditor will either approve the integration or ask the developer to make changes.
A guideline that can be adopted by the reviewer is to ask the following questions:
Style
- If this code was a chapter of a book would it seem written by a different author than the other chapters?
- If this code was a chapter of a book would it adopt narrative devices consistent with the rest of the chapters?
- If this code was a chapter of a book would it contain spelling mistakes?
Effectiveness
- If this code was a screwdriver would it be able to tighten the type of screw for which it was designed?
Maintainability
- If i would have to maintain this project would I trust the test suite?
- If i would have to maintain this project would I be confident that a change of mine would have no side effects on the operation of the system?
- If it were me to maintain this project would I be confident that updating one of its components would not have side effects on the operation of the system?
- If i would have to maintain this project would I have the information necessary to carry out an arbitrary task?
Before the expiry of a milestone all the features to be implemented will have been integrated, the responsibility for preparing the release will fall to a developer who will be release manager for that release, this role will be carried out in turn (with the aim of making everyone equally able to manage the entire lifecycle of the project).
Branching model
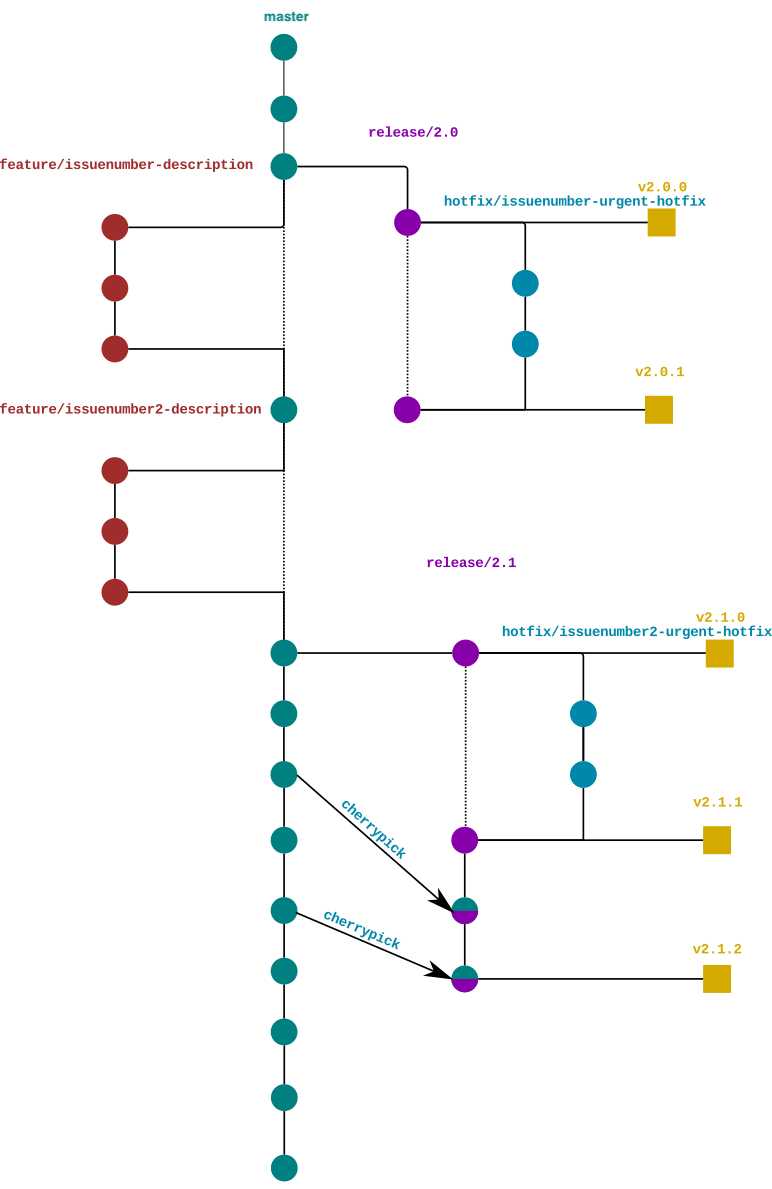
Master branch
This is the main branch; it is always synchronized with the latest release. The content of this branch is subject to all the mechanisms of code review and quality control during integration.
The software artifact obtained by compiling this branch is still to be considered a SNAPSHOT as it does not correspond to any formal release.
Feature branches
Feature branches are short term development branches, usually assigned to a developer and representing an atomic unit of code review and integration within the master branch.
Branch feature must adhere to the following feature/${issue-number}-{$description} naming convention
The software artifact obtained by compiling the code present in a feature branch is to be considered a SNAPSHOT useful to verify the proper functioning of the development unit
When developments are finished on a feature branch it is ready to be integrated with the master.
Release branches
The release branches track releases.
A new release branch is created when all feature branches required for a release have been integrated into the master branch and a new release must be made.
To support the backport of features to an already released version it is possible to integrate the feature branch also with a release branch or proceed to the cherry-picking of the content of the feature branch in the release branch.
Release branches must adhere to the following nomenclature
release/v${major}.{minor}
The artifact obtained from the compilation of the release branch is still to be considered a snapshot because a release branch may be subject to backport of new features or bug fixing
Hotfix branches
The hotfix branches are designed for fast and/or urgent fixes.
The hotfix branches are branched from the release on which they are to be made and are integrated directly on the same release, if the fix is also necessary on further releases and / or master the hotfix is cherry picked.
Hotfix branches must adhere to the following nomenclature
hotfix/${issue-number}-{issue-description}
Tags
Tags uniquely and immutably identify a precise commit that defines the content of a software release.
Tags must adhere to the following nomenclature
v${major}.${minor}.${patch}
The artifact obtained from the compilation of a tag is considered stable, its content is well defined and traceable and its version corresponds to the name of the tag.
Rebase Squash and Merge
AgileLab employs a git workflow based on rebase, squash and fast forward merges, we want to keep the history linear and avoid excessive branching, we want a git log that is feature centric, intermediate states (like WIP commits) where code is in a not buildable state are often noisy and lead developers not to consider the git log as a useful source of info.
To correctly comply with the git repository management guidelines, when implementing an issue with granularity:work-item, follow either Using Agile.Gitlab.Cli or Directly with Git and GitLab
Using Agile.Gitlab.Cli
[!Note] This section assumes that you already have a cloned repository and that the remote repository has been initialized with the Agile.Gitlab.Cli rules
[!Warning] If you are working on a repository with shared runners (e.g.
/PublicAgileFactory/handbook) and you push any commit to it the continuous integration pipelines will not trigger unless your account has been validated by Gitlab. Be aware that, in order to do so, a credit card is needed to show that you are real human user. No amount whatsoever is going to be charged by Gitlab but, if you don't feel comfortable doing this or if you don't have a valid credit card available, feel free to contact Internal IT/Servizi Sviluppatori.
Developer
- Choose an issue with label
granularity:work-item, for example, issue1title:Setup maven build - Ensure that the issue has either the
kind:featureor thekind:hotfixlabel - Run
lab issue start -i 1 -g AgileFactory -p $PROJECT_NAME -t $GITLAB_TOKEN, the tool will start an editor to let you edit the proposed merge request template, after you save the file and close the editor the lab tool will prompt that a branch calledfeature/1-setup-maven-buildand an associated merge request will be created asking for permission to proceed - The tool will print the git command to switch to the just created branch
- Develop your feature as usual, do as many commits are needed,
WIPcommits or broken states are fine while the merge request is inWIPstate - When development is finished, rebase onto the current master branch tip
- Signal to the maintainer of the repository that the issue is reviewable
lab issue phase -s reviewing -i 1 -g AgileFactory -p $PROJECT_NAME -t $GITLAB_TOKEN
[!Warning] Do not use git merge, if you need to synchronize with upstream master branch please rebase onto master. Never, Never, Never open feature branches from other feature branches.
Maintainer
- Once an issue is in
reviewingstate, please check that quality standards are met - Perform the needed code review
- Verify that the feature branch is still strictly ahead of the master branch, if not ask the developer to rebase his changes again
- Verify that the merge request description contains all the useful information about the feature, the description will become the squashed commit message of the whole feature
- Use
lab issue merge -i 1 -g AgileFactory -p $PROJECT_NAME -t $GITLAB_TOKENto squash the feature branch, generate the final commit message and fastforward merge intomaster
Directly with Git and GitLab
[!Warning] If you are working on a repository with shared runners (e.g.
/PublicAgileFactory/handbook) and you push any commit to it the continouos integration pipelines will not trigger unless your account has been validated by Gitlab. Be aware that, in order to do so, a credit card is needed to show that you are real human user. No amount whatsoever is going to be charged by Gitlab but, if you don't feel comfortable doing this or if you don't have a valid credit card available, feel free to contact Internal IT/Servizi Sviluppatori.
Developer
- Choose an issue with label
granularity:work-item, for example issue1title:Setup maven build - Ensure that the issue has either the
kind:featureor thekind:hotfixlabel - Click on the dropdown
Create merge requestand add the needed prefix to the proposed branch name (eitherfeature/orhotfix/) - Edit the merge request and choose a template from the
templatedropdown - Remember to replace
#with the correct issue id - Click
Check out branchand execute commands at step 1 - Develop your feature as usual and push your changes
- Signal to the maintainer of the repository that the issue is reviewable by removing
WIPfrom the title replacing anyphase:*label withphase:reviewingand assigning the merge request to the maintainer
Maintainer
- Once an issue is in
reviewingstate, please check that quality standards are met - Perform the needed code review
- Verify that the feature branch is still strictly ahead of the master branch, if not ask the developer to rebase his changes again
- Verify that the merge request description contains all the useful information about the feature, the description will become the squashed commit message of the whole feature
- Click
Check out branchand execute commands at step 1 to checkout branch locally - Squash all commits and use a single commit message with the recommended format
- Push the squashed branch
- Checkout the master branch
- Merge feature branch into the master branch without merge commit (fast forward)
- Push master branch
Recommended commit format
[#{{issue.iid}}] {{issue.title}}
{{mr.description}}
Squash and merge cheat sheet
Core assumption:
Intermediate commits in a feature branch are worthless to everyone not working on that feature.
Nobody cares about your "WIP", "fix typo", or "please work" commits. Promise.
Mental Model
flowchart LR
A["🌿 Your messy branch"] --> B["🗜️ Squash"] --> C["1️⃣ One beautiful commit"] --> D["⏩ Fast-forward onto main"]
| Operation | What it means |
|---|---|
| Fast-forward | "Pretend the branch always lived on main" |
| Squash | "Pretend the branch was always one commit" |
Your job: rewrite your feature branch into exactly one commit, then fast-forward main to it.
What Should I Do?
flowchart TD
A[Ready to merge?] --> B{Is main ahead
of your branch?}
B -->|No| C[🎉 Click Merge!]
B -->|Yes| D{Any conflicts?}
D -->|No| E[Click Rebase button in GitLab]
D -->|Yes| F{Pick your poison}
F --> G[git merge origin/main]
F --> H[git rebase origin/main]
G --> I[Push normally]
H --> J[Push with --force-with-lease]
I --> K[Pipeline runs]
J --> K
E --> K
K --> C
Happy Path 🌈
You're fast. Nobody touched main. The gods smile upon you.
gitGraph commit id: "A" commit id: "B" branch feature/my-branch commit id: "f1" commit id: "f2"
Click Merge in GitLab. Done. Go get coffee.
Result:
gitGraph commit id: "A" commit id: "B" commit id: "Your feature ✨"
Less Happy Path 😅
Someone pushed to main while you were working. Rude.
gitGraph commit id: "A" commit id: "B" branch feature/my-branch commit id: "f1" commit id: "f2" checkout main commit id: "D (someone else)"
GitLab says: "Fast forward merge is not possible. Please rebase."
No Conflicts?
Click Rebase in GitLab UI. (Not "Rebase without pipeline" — trust no one, including yourself.)
Conflicts?
Pick one approach and stick with it for the branch's lifetime:
| Approach | Commands | Push |
|---|---|---|
| Merge | git fetch && git merge origin/main |
git push |
| Rebase | git fetch && git rebase origin/main |
git push --force-with-lease |
⚠️ Mixing merge and rebase on the same branch leads to suffering.
Either way: pipeline runs → Merge button activates → click it → victory.
Manual Workflow (Old School)
For when GitLab can't help you, or you enjoy doing things the hard way.
flowchart LR
A[1. Fetch] --> B[2. Squash commits] --> C[3. Rebase onto main] --> D[4. Force push] --> E[5. Merge]
1–2. Fetch & Squash
git fetch origin
git checkout feature/my-branch
git rebase -i $(git merge-base --fork-point origin/main)
Your editor opens. Mark everything except the first commit as s:
pick a1b2c3 First commit
s d4e5f6 Second commit
s 789abc Third commit
Write a good commit message. This is permanent history now.
3. Rebase onto main
git rebase origin/main
Conflicts? Fix them, git add, then git rebase --continue. Repeat until done.
4. Push (safely)
git push --force-with-lease
--force-with-lease= "force push, but fail if someone else pushed first"If this makes you nervous, good. Healthy fear.
5. Merge
git checkout main
git merge --ff feature/my-branch
git push
🎉 You did it.
Daily Life: Staying in Sync
Sometimes you need changes from main before you're ready to merge.
flowchart TD
A[Need changes from main?] --> B{Your preference?}
B -->|I like merge| C[Suffer later 😈]
B -->|I like rebase| D[Suffer now 😇]
If You Merge Periodically
When it's finally merge time, skip the rebase headaches with this trick:
git checkout feature/my-branch
git fetch && git merge origin/main
git reset --soft origin/main
git commit -am 'My beautiful, final, squashed message'
git push --force-with-lease
It's dirty. It works.
If You Rebase Periodically
Squash before rebasing to avoid fixing the same conflict 47 times:
# Squash first
git rebase -i $(git merge-base --fork-point origin/main)
# Then rebase
git rebase origin/main
# Then push
git push --force-with-lease
Alternative squash method (no interactive editor):
```bash git reset --soft $(git merge-base --fork-point origin/main)
git commit -am 'nice cumulative message' ```